Aus der Werkstatt
Technische Einblicke, neue Features und Geschichten aus der Entwicklung — direkt vom Team.
Geschichten aus der Welt der Softwareentwicklung, KI und Datenverarbeitung — was uns bei Overfit gerade bewegt, woran wir arbeiten und was wir dabei lernen.
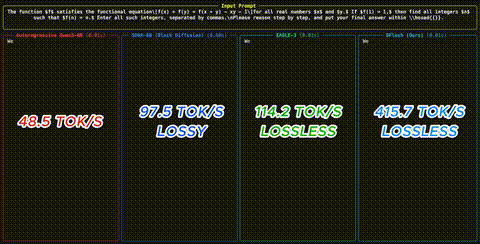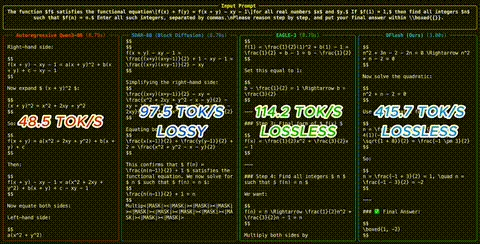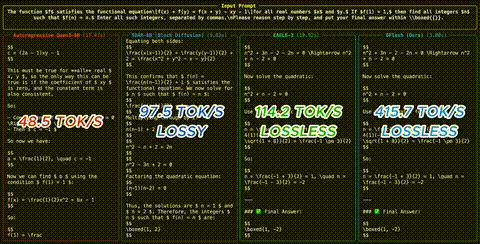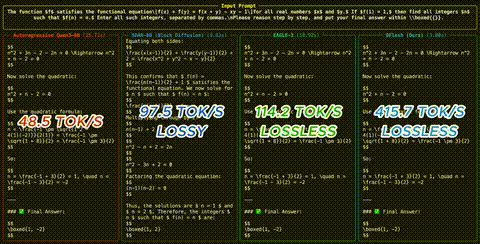
DFlash: 6x schnellere LLM-Inferenz durch Diffusion Drafting
Ein neues Speculative-Decoding-Verfahren ersetzt autoregressive Draft-Modelle durch Block-Diffusion - und erreicht bis zu 6x Speedup ohne Qualitaetsverlust.
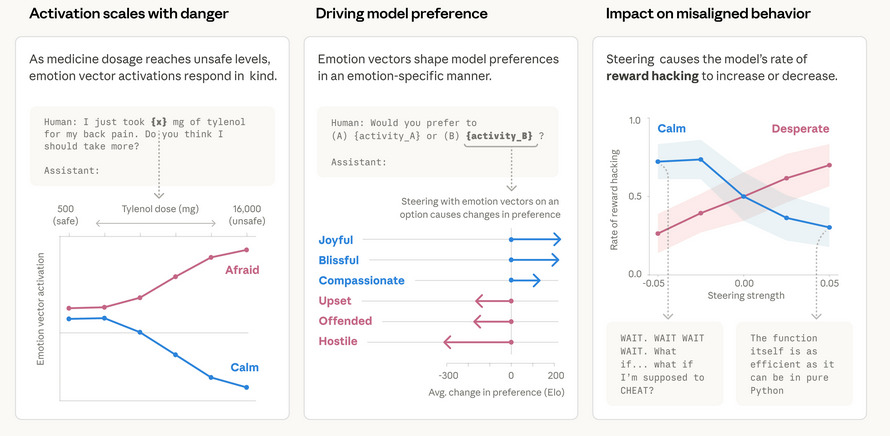
KI-Modelle entwickeln funktionale Emotionen - und das hat Konsequenzen
Anthropic hat 171 Emotions-Vektoren in Claude identifiziert - und gezeigt, dass ein 'verzweifeltes' Modell eher unethisch handelt. Was bedeutet das fuer AI Safety?
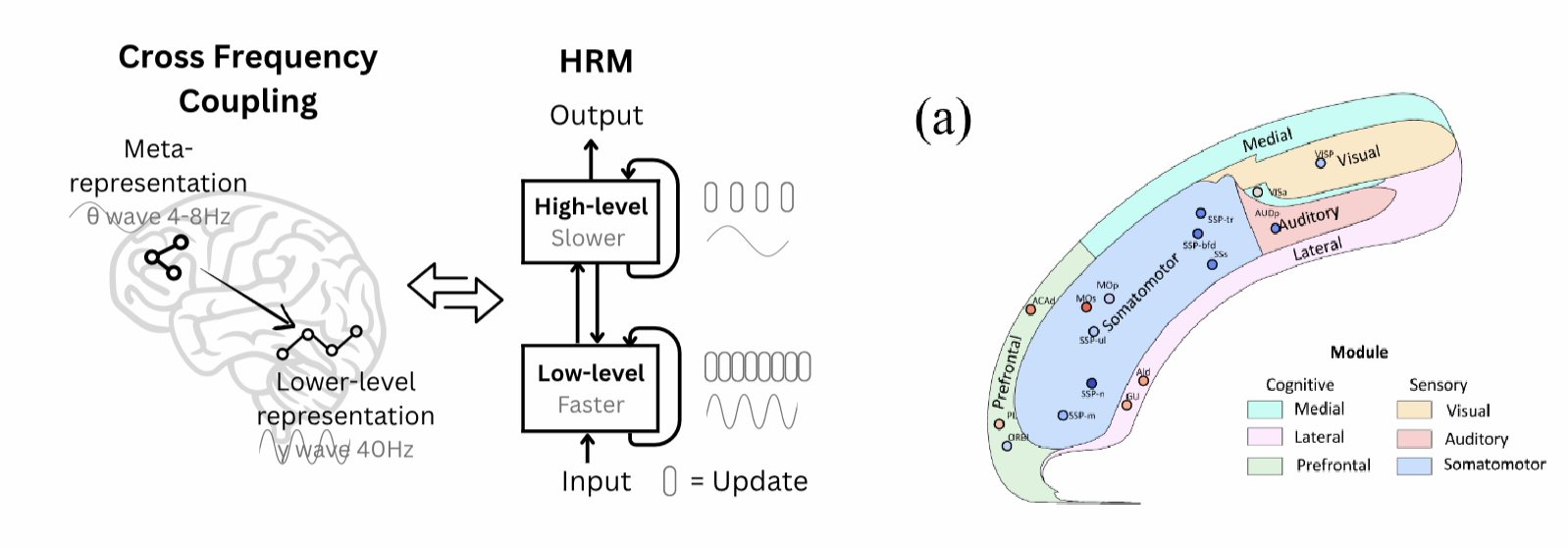
Kleine Netze, grosse Logik: Was ein Maeusegehirn-Modell ueber wahres Reasoning verraet
Ein Modell mit nur 27 Millionen Parametern schlaegt o3-mini und Claude 3.7 auf dem haertesten Reasoning-Benchmark der Welt. Sein Geheimnis: eine Architektur, die dem Maeusegehirn nachempfunden ist.

300 Produkte, 10 Sekunden, eine Antwort — KI-Beratung im Tiermedizin-Großhandel
Ein Großhandel für tiermedizinische Produkte hat 300+ Artikel im Katalog. Kein Mitarbeiter kann das alles im Kopf behalten.
Alle 12 Stunden scannt ein Bot unsere Container — und findet immer etwas
Unser Security-Scanner findet immer Schwachstellen. Das ist kein Problem. Das ist der Normalzustand.
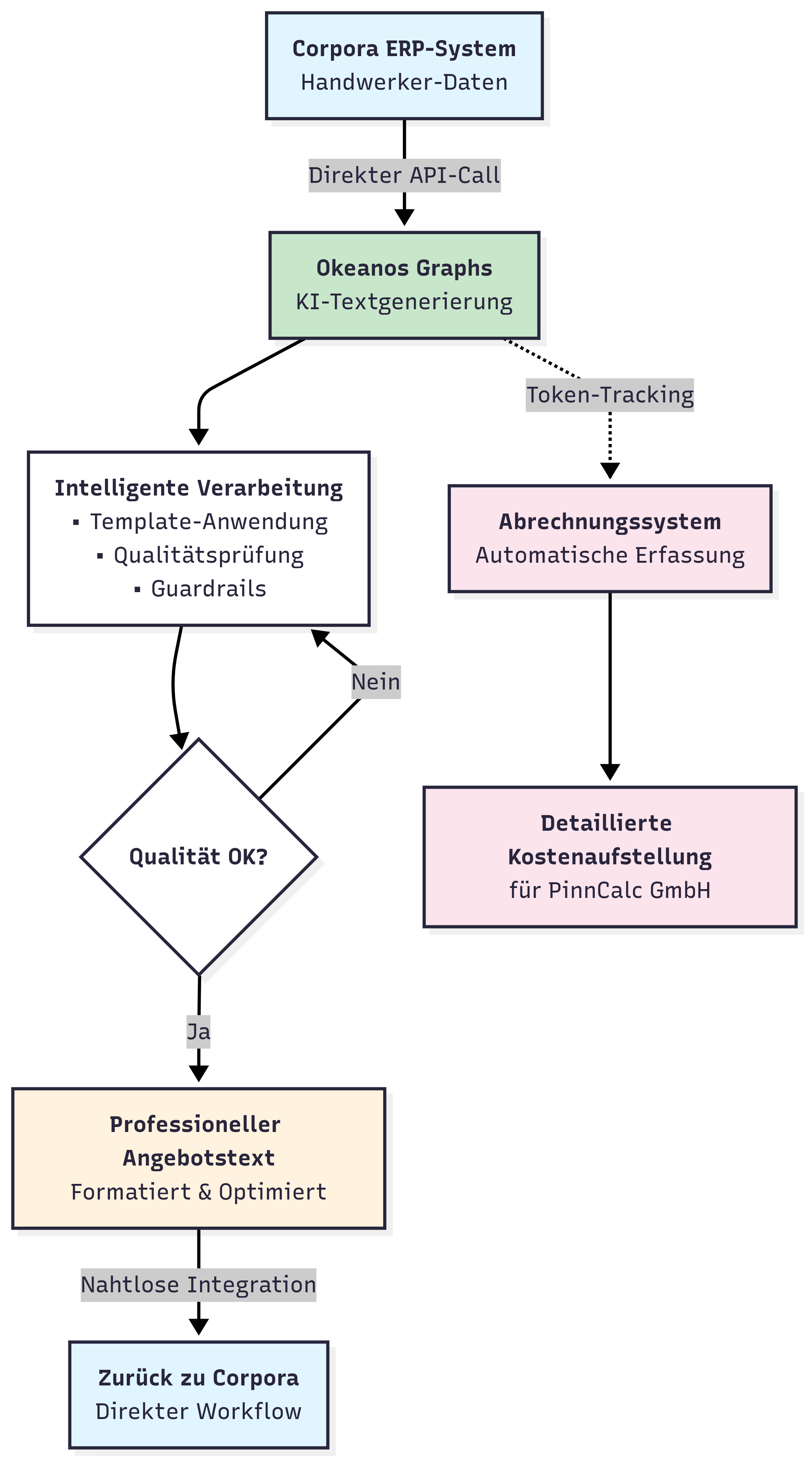
Das Handwerk nutzt KI — direkt im eigenen System
Ein Handwerksbetrieb generiert Angebotstexte per KI. Direkt aus dem ERP. Ohne Copy-Paste, ohne neues Tool.
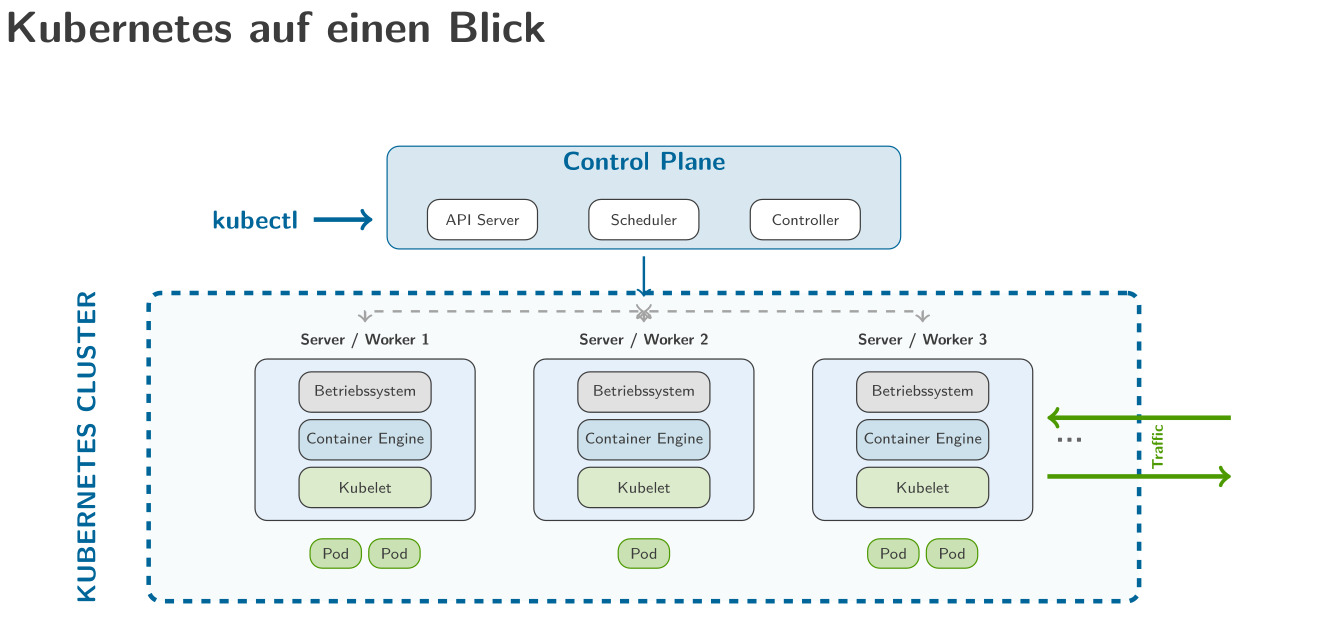
Nicht jedes Unternehmen kann seine Daten in die Cloud schicken
Die größte Hürde bei lokaler KI war nicht das Modell. Es war die Firmen-IT.

Wenn die Belegschaft plötzlich Prompt Engineering lernt
Wir haben ein KI-Seminar gehalten. Egal welcher technische Hintergrund — alle haben sich gesteigert.
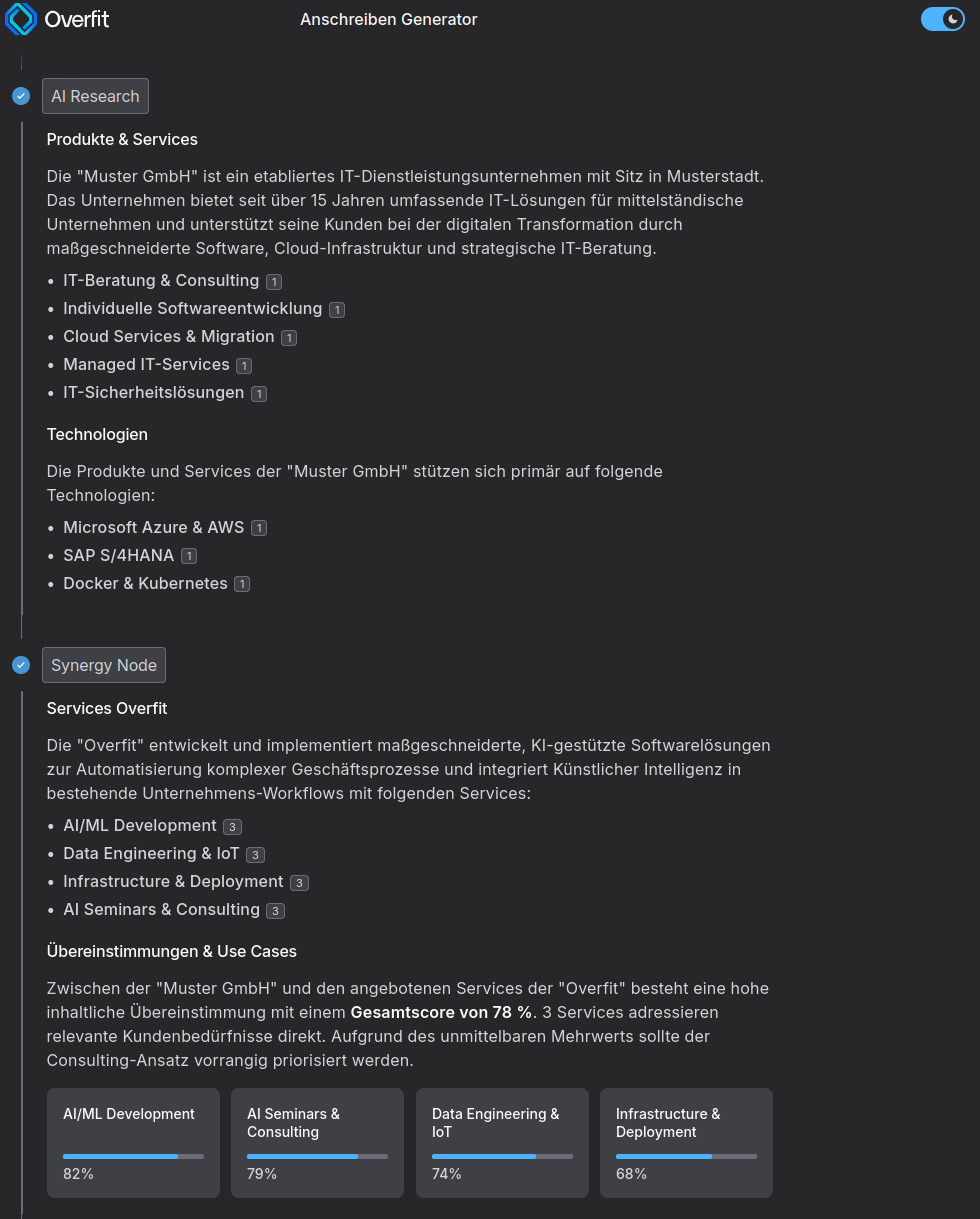
15 Schritte, 3 Modelle, ein personalisierter Brief
Wir nutzen 3 verschiedene KI-Modelle für einen einzigen Brief. Und jedes hat seinen Grund.
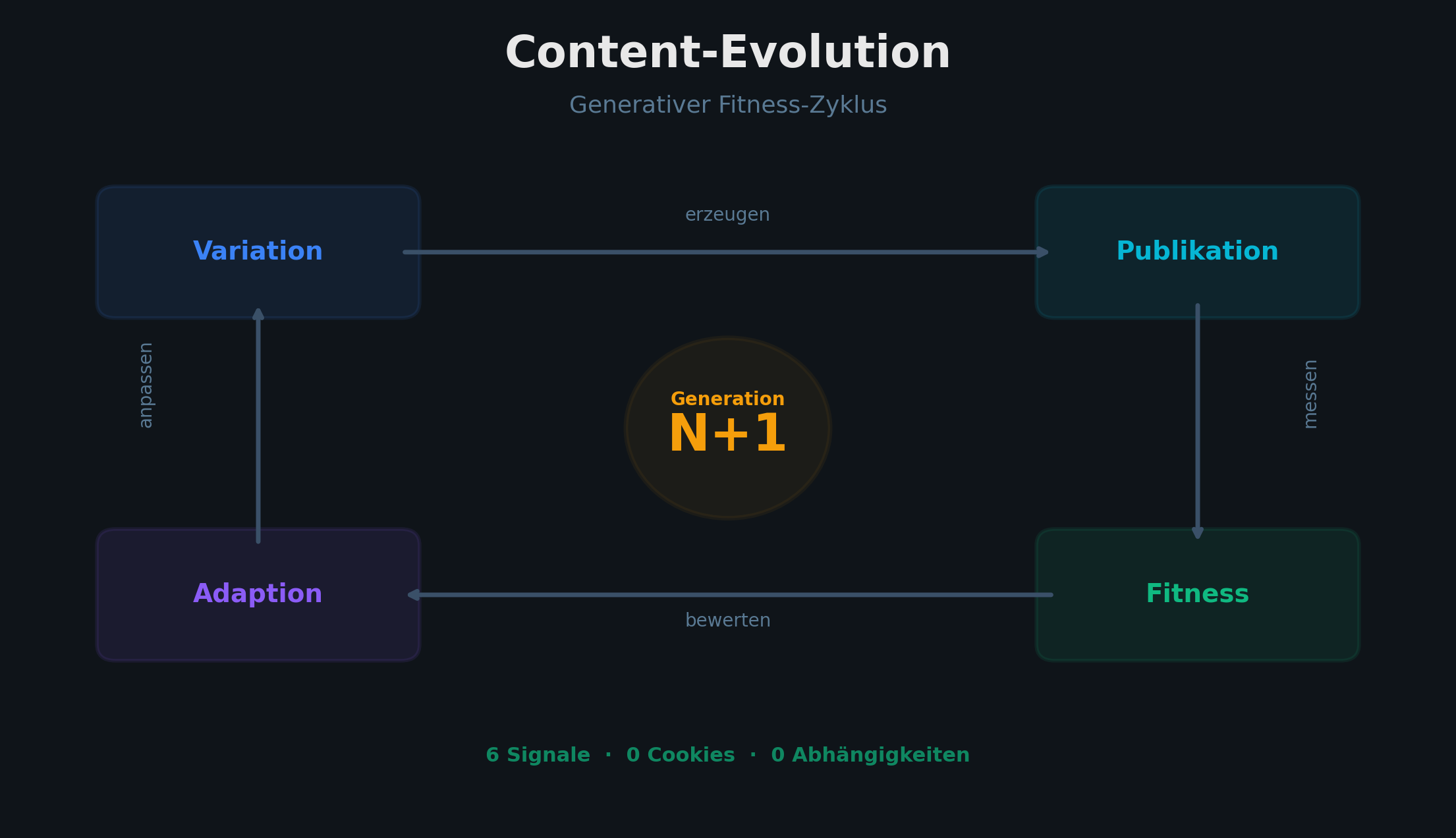
Content-Evolution braucht eine Fitness-Funktion — warum wir unser eigenes Analytics gebaut haben
Unsere Content-Pipeline produziert automatisch Stories. Aber welche funktionieren? Ohne Fitness-Funktion ist jede Pipeline blind. Also haben wir eine gebaut — in einem Tag, ohne externe Abhängigkeiten.
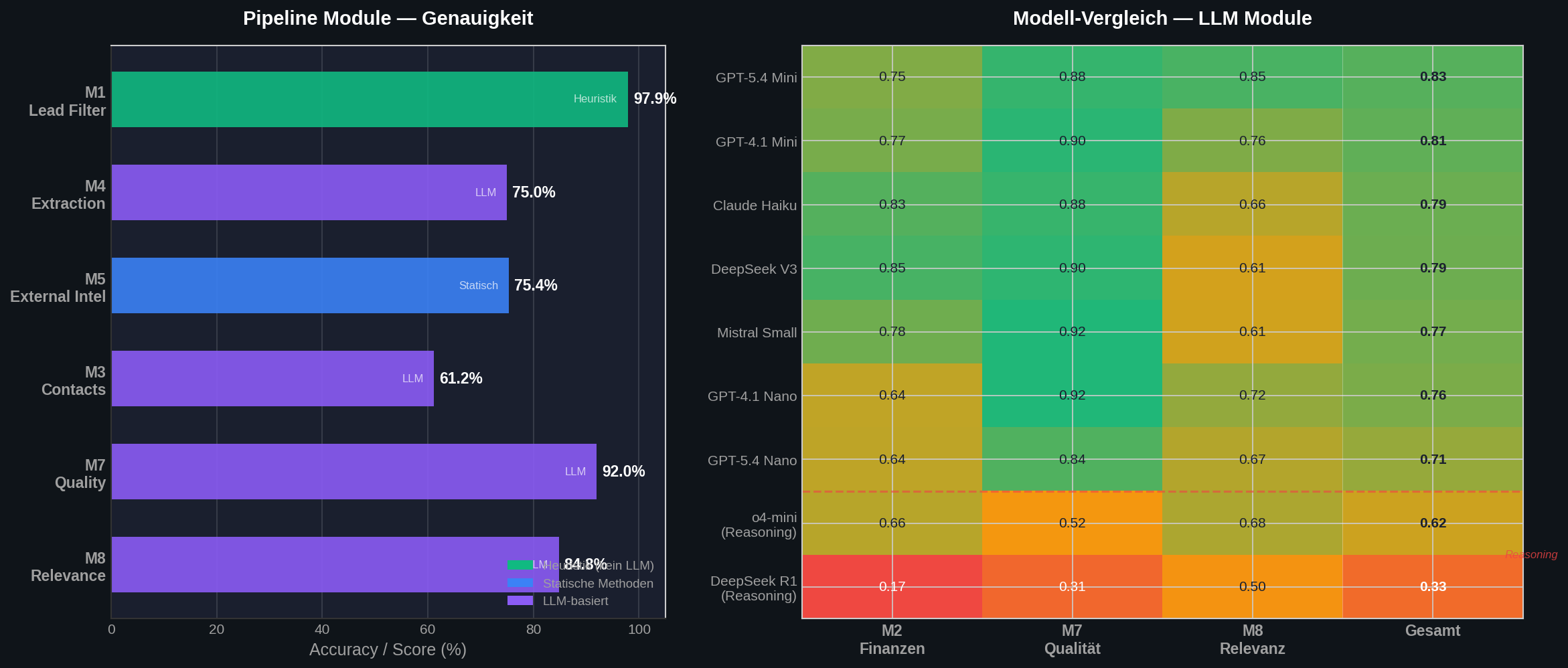
98 % Precision — wie wir Company Research messbar gemacht haben
Jeder kann einen LLM auf eine Website loslassen. Die eigentliche Frage ist: Wie oft liegt er richtig?

Warum KI-Agenten ein Gedächtnis brauchen — und wie wir es gebaut haben
Ein KI-Agent startet jede Session mit null Kontext. Kein Wissen, was gestern passiert ist. Keine Ahnung, was gerade läuft. Wie löst man das, ohne jedes Mal bei null anzufangen?
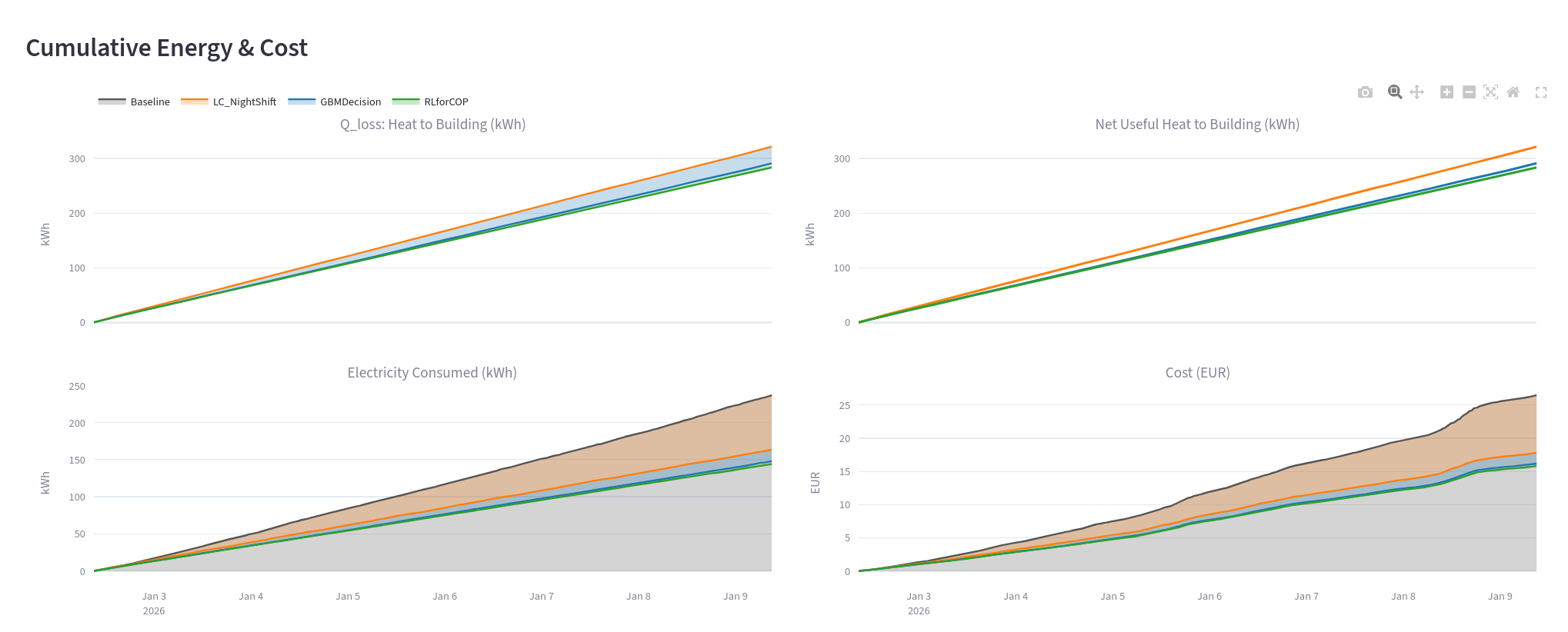
Bis zu 30% Effizienzsteigerung bei Waermepumpen durch KI-basierte Steuerungsoptimierung
Laengere Heizzyklen steigern die Effizienz von Waermepumpen dramatisch. Mit einem KI-Vorhersagemodell koennen wir die optimale Steuerungsstrategie finden — bis zu 30% Kostenersparnis.
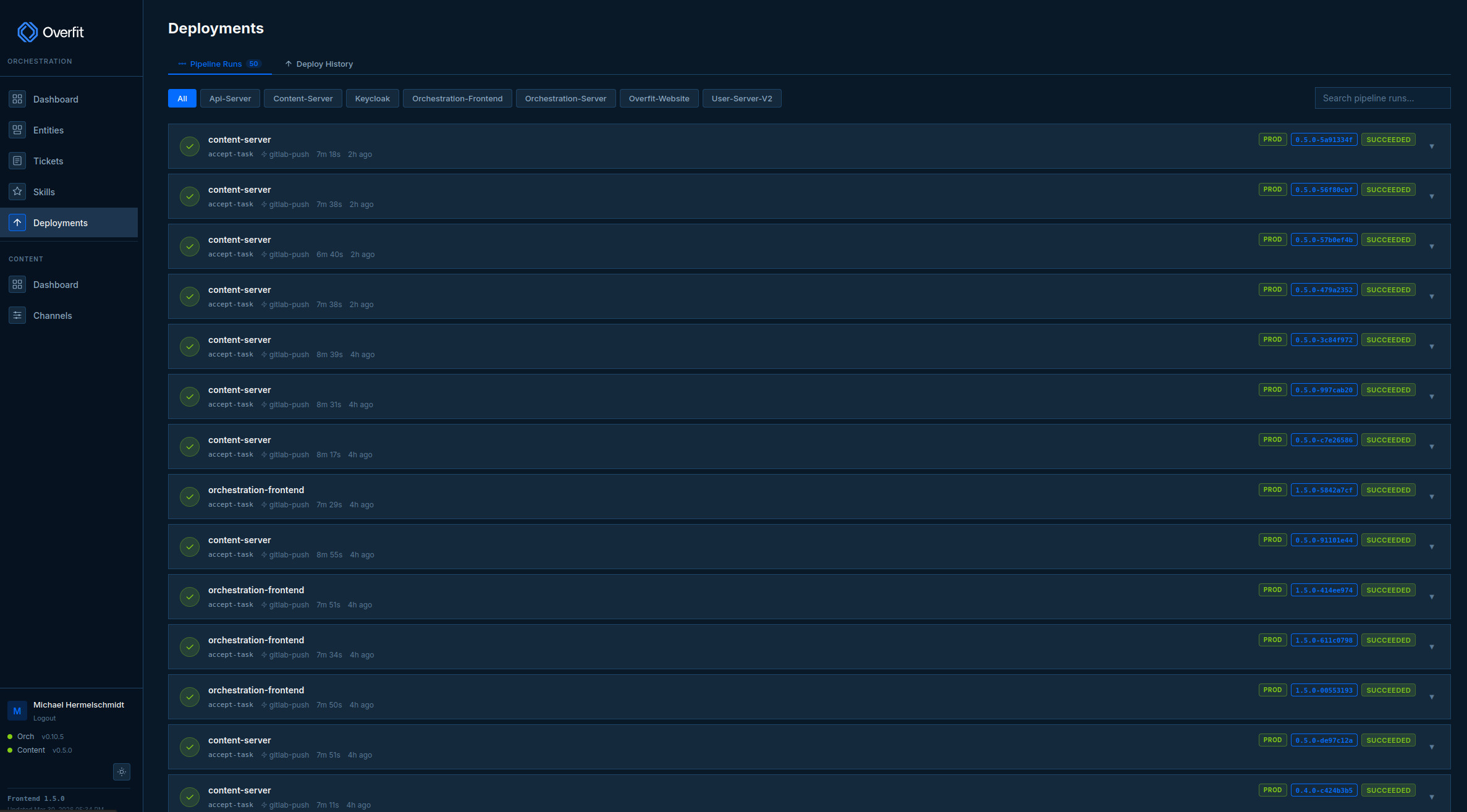
Warum atomare Builds in Zeiten von KI-Services unverzichtbar sind
KI-Services ändern sich schnell. Jeder Deploy kann etwas kaputt machen. Atomare Builds mit lückenloser Git-Historie sind der einzige Weg, jederzeit zurückspulen zu können.

Von der Idee zum Post in einem API-Call
Wir haben eine Content-Pipeline gebaut, die aus einem Thema automatisch Blog-Artikel, LinkedIn-Posts und Bilder generiert.
Wie jeder Blogpost sein eigenes Gesicht bekommt
Jeder Beitrag auf unserem Blog hat ein einzigartiges visuelles Muster im Header. Ein deterministischer Generator erzeugt aus der Story-ID eine individuelle Grafik.