Das Bottleneck-Problem
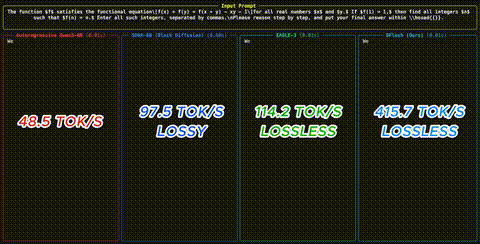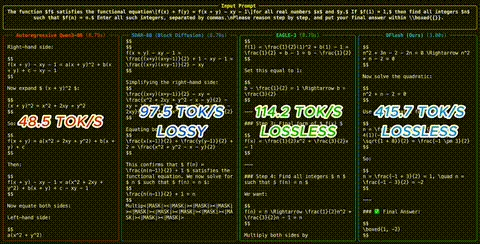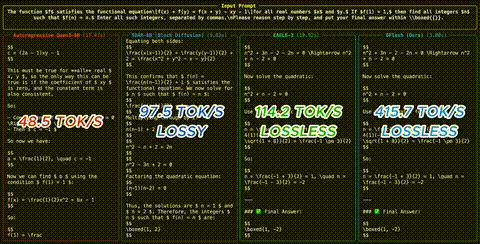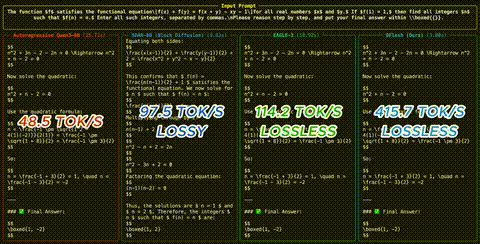
LLM-Inferenz ist von Natur aus sequentiell - jedes Token haengt vom vorherigen ab. Speculative Decoding ist der vielversprechendste Ansatz, dieses Bottleneck zu brechen: Ein kleines Draft-Modell schlaegt Tokens vor, das grosse Modell verifiziert sie parallel. Doch selbst der bisherige Spitzenreiter EAGLE-3 draftet noch autoregressiv und erreicht praktisch nur 2-3x Speedup.
Zwei Innovationen, ein Durchbruch
DFlash von Z Lab kombiniert zwei elegante Ideen zu einem neuen Paradigma:
Target-konditioniertes Drafting: Grosse LLMs kodieren in ihren Hidden States implizit Informationen ueber kommende Tokens. DFlash extrahiert Feature-Vektoren aus mehreren Schichten des Zielmodells und konditioniert sein Draft-Modell darauf. Ein 'Free Lunch' - die Information ist bereits da, man muss sie nur nutzen.
Paralleles Diffusion-Drafting: Statt Token fuer Token zu generieren, erzeugt DFlash alle Draft-Tokens in einem einzigen Forward Pass durch Block-Diffusion. Die Kosten bleiben konstant, unabhaengig von der Blockgroesse. Ein DFlash-Modell mit mehreren Schichten, das 16 Tokens draftet, kann schneller sein als ein einschichtiges EAGLE-3 mit 8 Tokens.
Die Zahlen sprechen fuer sich
Die Benchmarks sind beeindruckend: Bis zu 6x lossless Speedup auf Qwen3-8B ueber Math-, Coding- und Chat-Benchmarks. Fast 2.5x schneller als EAGLE-3 auf den meisten Aufgaben. Auch unter Sampling (temperature=1) und im Reasoning-Modus bleiben starke Speedups erhalten - etwa 4.5x fuer Reasoning-Modelle.
Depth-Scaling: Eine neue Achse
Besonders spannend ist die Depth-Scaling-Eigenschaft: Anders als bei autoregressiven Draftern verbessert sich die Akzeptanzlaenge bei DFlash mit der Tiefe des Draft-Modells. Das eroeffnet eine neue Skalierungsachse - mehr Schichten im Drafter bedeuten proportional bessere Ergebnisse, nicht nur marginale Verbesserungen.
Sofort einsetzbar
DFlash ist keine reine Forschung - es kommt mit fertigen Integrationen fuer SGLang (Produktion) und Transformers (Exploration). Eine vLLM-Integration ist in Arbeit. Fuer Teams, die grosse Inferenz-Workloads betreiben, ist der 6x Speedup als Drop-in sofort nutzbar.
Die vollstaendigen Ergebnisse und der Code sind auf der Z Lab Projektseite verfuegbar.