Wenn 27 Millionen Parameter reichen
Die KI-Branche hat sich an ein Mantra gewoehnt: groesser ist besser. Mehr Parameter, mehr Daten, mehr Rechenleistung. Doch ein neues Paper aus Singapur stellt diese Annahme grundlegend in Frage — und die Ergebnisse sind schwer zu ignorieren.
Das Hierarchical Reasoning Model (HRM) kommt mit gerade einmal 27 Millionen Parametern aus. Zum Vergleich: aktuelle Frontier-Modelle haben hunderte Milliarden. Trotzdem erreicht HRM auf dem ARC-AGI-Benchmark — einem der anspruchsvollsten Tests fuer abstrakte Intelligenz — eine Accuracy von 40,3%. Das uebertrifft sowohl o3-mini-high (34,5%) als auch Claude 3.7 mit 8K Context (21,2%).
Maeuse als Vorbild
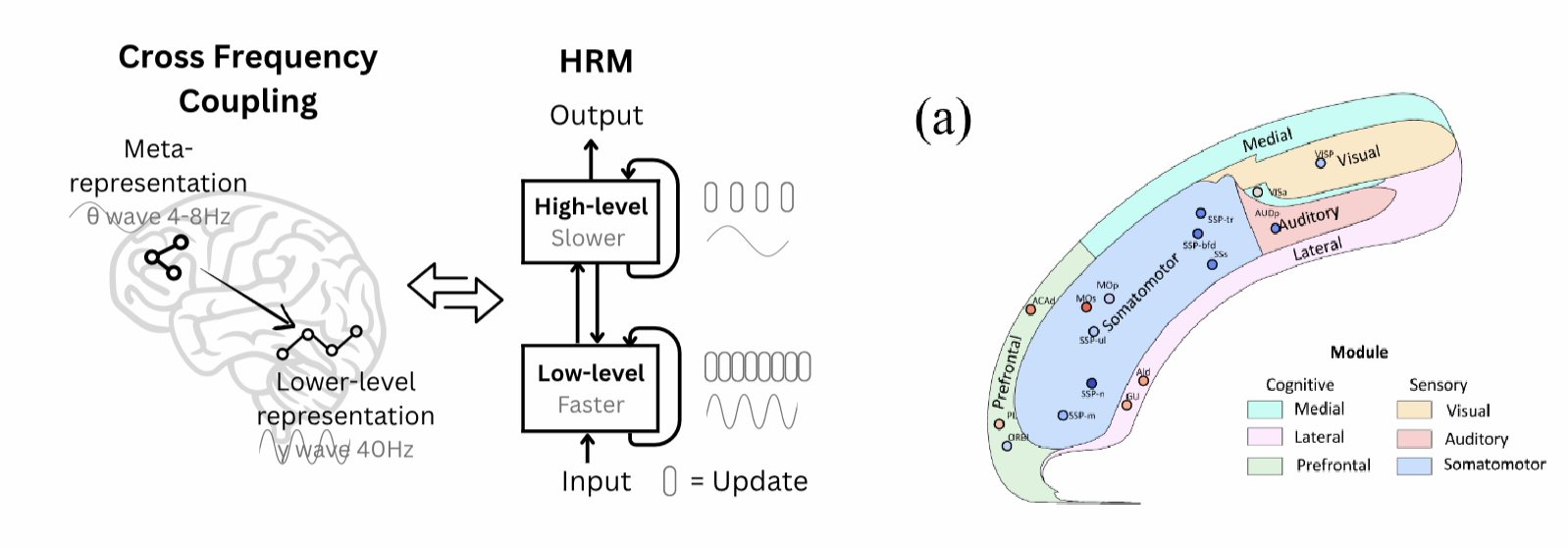
Kleine Netze koennen grossen die Stirn bieten — wenn sie clever aufgebaut sind. Die Architektur des HRM ist direkt vom Maeusegehirn inspiriert. Zwei rekurrente Module arbeiten auf unterschiedlichen Zeitskalen zusammen: Ein High-Level-Modul fuer langsame, abstrakte Planung und ein Low-Level-Modul fuer schnelle, detaillierte Berechnungen. Das entspricht der Cross-Frequency Coupling im Cortex — langsame Theta-Wellen (4-8 Hz) steuern schnelle Gamma-Wellen (30-100 Hz).
Das Ergebnis ist eine emergente Dimensionalitaets-Hierarchie, die verblueffend nah an der des echten Maeusegehirns liegt. Das Verhaeltnis der Repraesentationsdimensionen zwischen High- und Low-Level-Modul (ca. 2,98) entspricht fast exakt dem, was Neurowissenschaftler im Maeusegehirn messen (ca. 2,25).
Wahre logische Problemfaehigkeit
Was HRM besonders macht: Es loest Probleme, an denen Chain-of-Thought-Modelle komplett scheitern. Auf Sudoku-Extreme erreicht HRM 55% Accuracy — waehrend alle CoT-Baselines bei 0% stehen. Bei der optimalen Pfadsuche in 30x30-Labyrinthen: 74,5% fuer HRM, 0% fuer die Konkurrenz.
Und das alles mit nur 1.000 Trainingsbeispielen. Kein Pre-Training. Kein Chain-of-Thought. Maeuse-gehirn-aehnliche Strukturen sind ein intelligenter Weg, um schwere Probleme zu knacken.
Was das fuer die Praxis bedeutet
HRM ist kein Ersatz fuer Large Language Models — es verarbeitet keine natuerliche Sprache. Aber es zeigt etwas Fundamentales: Wahre logische Problemfaehigkeit entsteht nicht durch Skalierung, sondern durch Architektur. Die hierarchische Trennung von abstraktem Denken und schneller Ausfuehrung — genau so, wie es das Gehirn macht — eroeffnet einen voellig neuen Pfad fuer KI-Reasoning.
Die Frage ist nicht mehr nur "Wie gross kann das Modell werden?", sondern: "Wie clever ist seine Struktur?"